基于分析access.log打造网站访问统计功能
第三发网站访问统计 很多,有Umeng、百度、Google统计等,这些统计都较为成熟,使用也挺方便的,这些都是通过前端加入js 做统计的。
然而在服务器上,基于Web 服务的日志,也能简单做个访问统计功能,其脚本不会很复杂,代码行数也就百来行而已。本文的博客环境是Apache + Mysql + WordPress,文章就是基于该环境做介绍。
一、功能框架图
先来个架构图说明,如下:
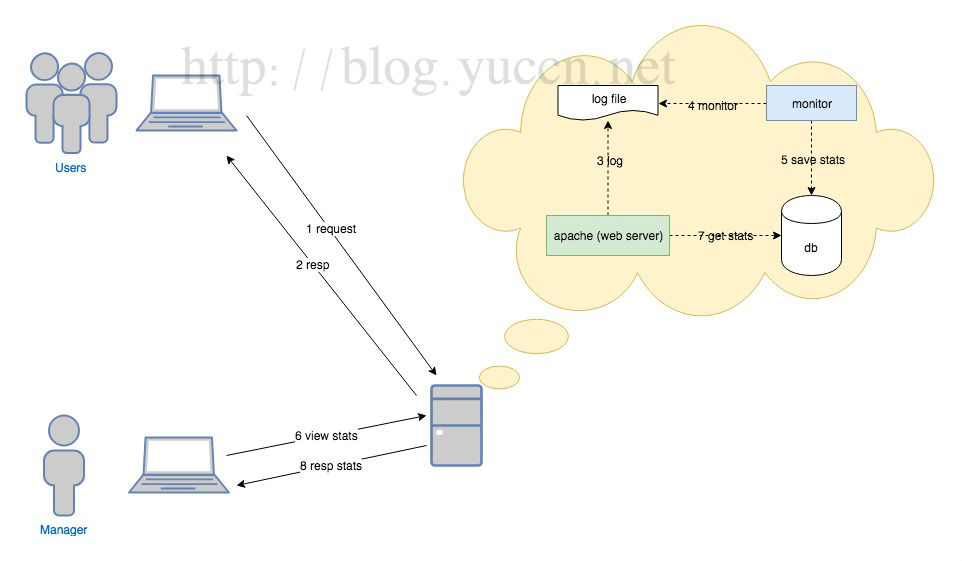
二、日志自定义
编辑 apache2.conf,增加如下自定义 Log 格式,主要使得方便后面做读取分析。
LogFormat "\"%h\" \"%{%Y-%m-%d %H:%M:%S}t\" \"%r\" \"%>s\" \"%{Referer}i\" \"%{User-Agent}i\"" custom这些参数说明可以找apache日志格式说明查阅,这里定义日志格式为:
“ip” “时间” “请求行” “http 状态” “referer” “user-agent”
编辑网站配置,使用自定义格式,如下:
....
....
CustomLog ${APACHE_LOG_DIR}/blog_access.log custom重启 apace
/etc/init.d/apache2 restart
如果Apache 收到该域名下资源的请求,日志就会按照指定格式写入对应文件了
三、设计数据库
创建请求纪录表,增加自己所关注的字段,这里是 ip,和请求路径,模式等。
db_request {
`id`
`IP`
`path`
`mode`
`os`
`status`
`user_agent`
`referer`
`time`
}增加统计表,用于记录总请求数和几个主流的爬虫,主流爬虫有 baidu、google、sogou、360、bing等。
db_stats {
`date_time`
`request_count`
`baidu_bot_count`
`google_bot_count`
`sogou_bot_count`
`360_bot_count`
`bing_bot_count`
`other_bot_count`
}四、增加分析日志记录脚本
脚本使用python编写,在python3 下运行,主要思想为创建子进程,使用tail -F 捞取日志信息,由于日志格式上面已经做了格式化,读取文件行后,解析较为简单,主要读取解析出关注的字段,并把它保存到上面设计的数据库内,供后面展示使用。代码为monitor.py,由于代码较长,所以放到文章后面(八)贴出。
由于有些请求是加载样式脚本等资源的,如css、js等,这些资源的请求不能算正常访问,统计时候需要忽略这些。
五、设置随系统启动
脚本写完后,需要把脚本作成一个随系统启动程序,省得每次重启机器都要手动去启动脚本,linux 下设置程序随系统启动的方法为,在/etc/rc.local 内增加启动信息。本脚本纪录为 rc.local文件中增加这样一行:
/usr/bin/python3 /脚本路径/monitor.py &六、增加查看页面
增加一个页面,读取访问信息展示出来,较为简单,这里做下简单地介绍下在wp 下自定义访问数据库页面。
在自己的themes下的主题目录下建立一个stats.php,即可自由访问指定数据库,在里面写上读取数据库和输出html 格式内容的代码。再在wp 管理里面,新建一个页面,保存后,wp 会为该页面管理到一个id,如下:
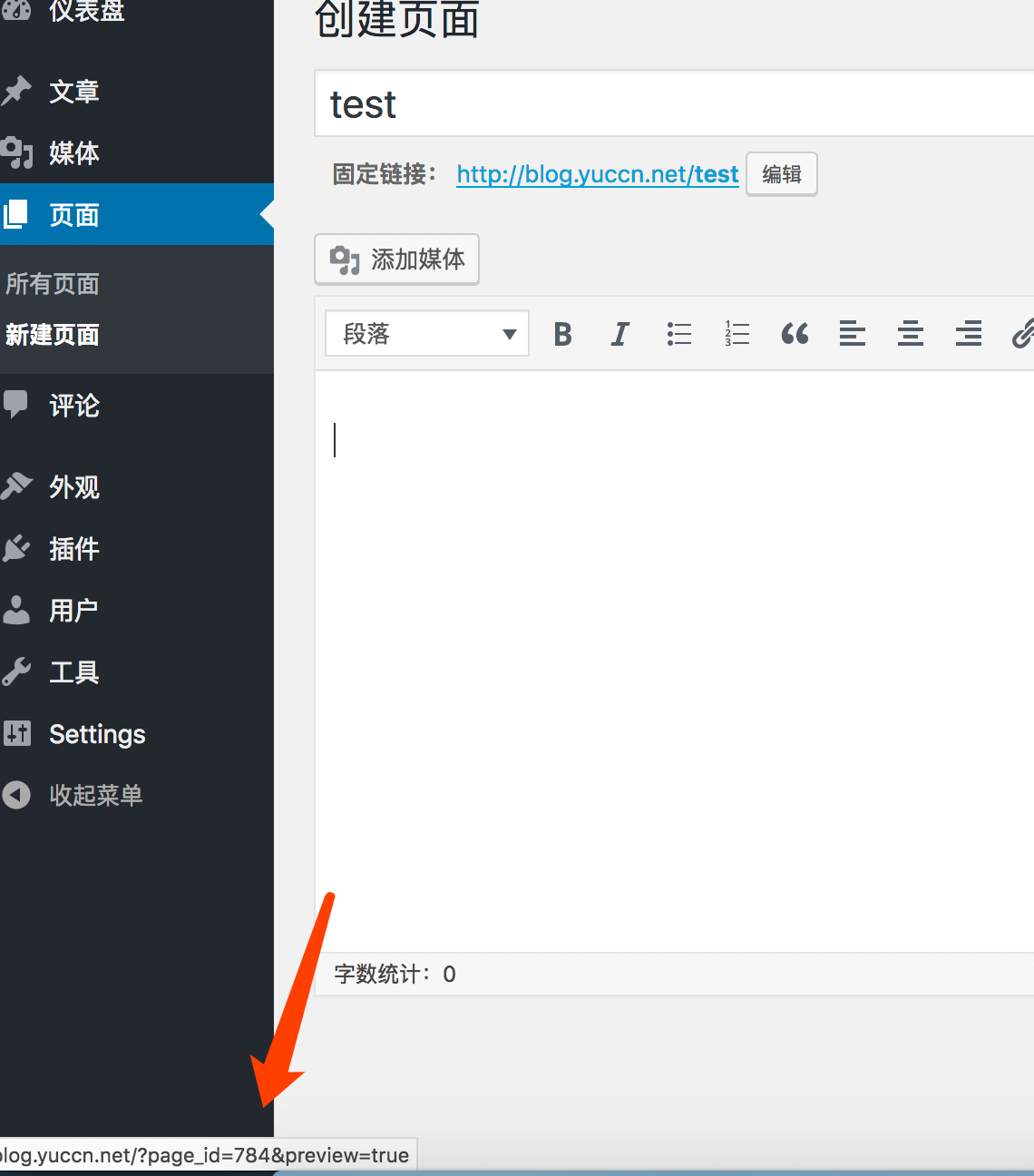
之后通过修改主题内的page.php 文件:
// 前面很多代码
if ( is_page(784) ){
include(TEMPLATEPATH .'/stats.php');
}
else {
// 原来的代码
}
// 后面很多代码这样便可达到了自定义wp 页面了,同时也保持了自己主题的页面风格,效果:
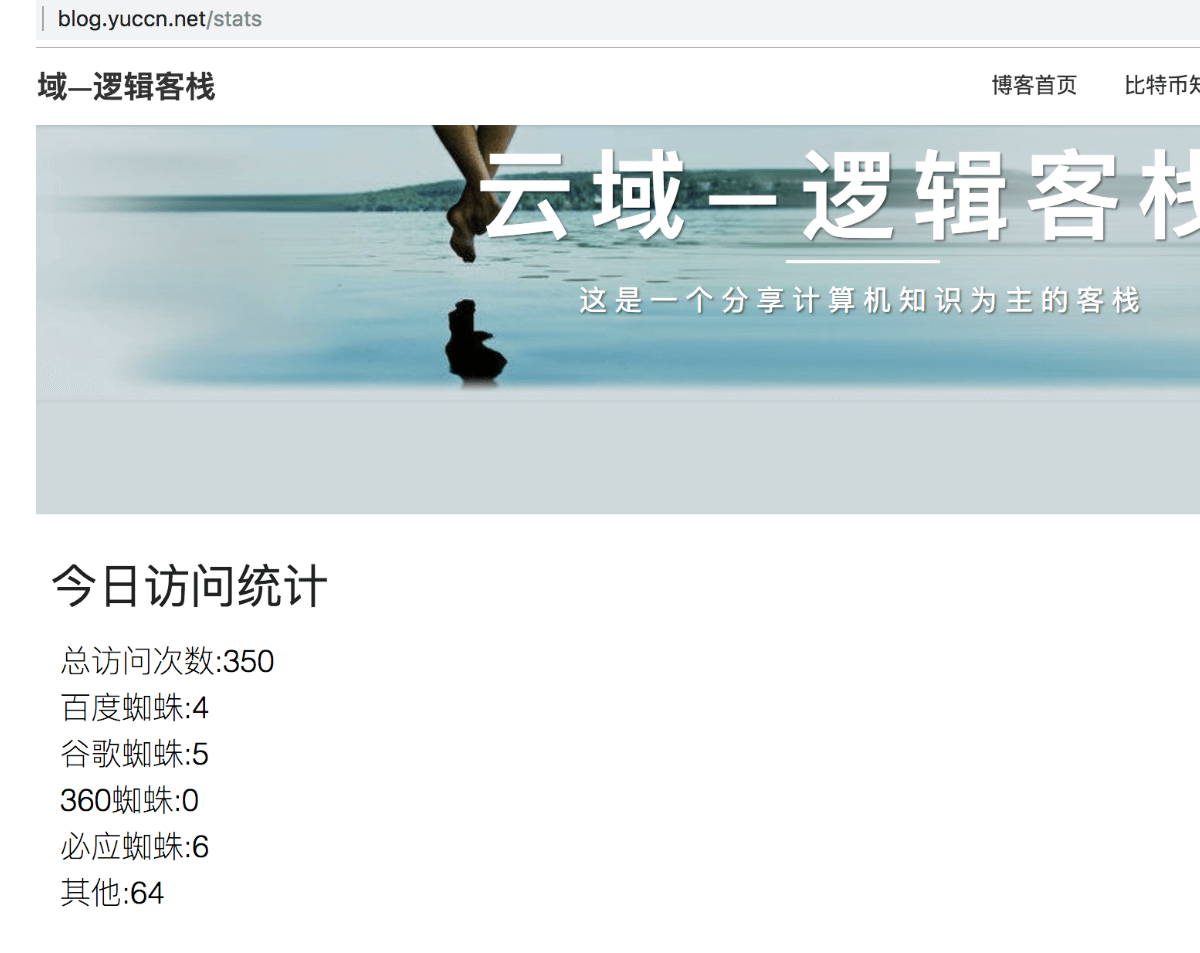
七、优缺点
这样统计,相对第三方统计,可以更清楚看到服务器的原始请求,稍作分析也可以分析出网站的一些非法请求,比如被恶意请求、野蜘蛛等信息。但也存在明显的缺点,第三方统计是基于终端浏览器的,统计行为服务器不参与,而这里的统计在服务器脚本执行,这样也浪费了的部分资源;如果网站配置CDN,那这种统计就不准确了。
八、代码
#-*- coding: UTF-8 -*-
import shlex, subprocess
import time
import pymysql
log_file = "/var/log/apache2/你的日志名.log"
db_user = "数据库用户名" # 最好新建一个低一点权限的用户
db_pwd = "数据库密码"
db_host = "localhost"
db_name = "数据库名"
# 浏览器特征,浏览器名字,类型
user_agent_map = [
["firefox", "Firefox", ""],
["chrome", "Chrome", ""],
["msie", "IE", ""],
["safari", "Safari", ""],
["micromessenger", "微信", ""],
["googlebot", "Google 蜘蛛", "google_bot_count"],
["baiduspider", "Baidu 蜘蛛", "baidu_bot_count"],
["sogou web spider", "Sogou 蜘蛛", "sogou_bot_count"],
["bingbot", "Bing 蜘蛛", "bing_bot_count"],
["360spider", "360 蜘蛛", "360_bot_count"],
["spider", "其它 蜘蛛", "other_bot_count"],
["bot", "其它 蜘蛛", "other_bot_count"],
[" ", "-", ""],
]
os_map = [
["mac os", "Mac"],
["windows", "Windows"],
["iphone", "Iphone"],
["android", "Android"],
[" ", "-"],
]
ignore_type_items = [
".css",
".php",
".js",
".jpg",
".png",
".gif",
".bmp",
".woff2",
".ico",
".txt"
]
def is_ignore_path(path):
index = path.rfind(".")
if index == -1:
return False
path_type = path[index:]
for item in ignore_type_items:
if path_type == item:
return True
return False
def get_user_agent_item(user_agent):
for item in user_agent_map:
if user_agent.find(item[0]) != -1:
return item
return user_agent_map[len(user_agent_map) - 1]
def get_os(user_agent):
for item in os_map:
if user_agent.find(item[0]) != -1:
return item[1]
return os_map[len(os_map) - 1][1]
#http://www.runoob.com/python3/python3-mysql.html
def save(ip, request_time, path, status, user_agent, referer, mode):
index = path.find("?")
if index != -1:
path = path[:index]
if is_ignore_path(path):
print("path ignore,ip:" + ip + ",mode:" + mode + ",path:" + path + "\n")
return
date_time = request_time[:request_time.find(" ")]
request_time = time.strptime(request_time,'%Y-%m-%d %H:%M:%S')
request_time = int(time.mktime(request_time)) * 1000
user_agent = user_agent.lower()
user_agent_item = get_user_agent_item(user_agent)
user_agent_name = user_agent_item[1]
os_name = get_os(user_agent)
db = pymysql.connect(db_host, db_user, db_pwd, db_name)
cursor = db.cursor()
# 请求记录
sql = "INSERT INTO `db_request`(`IP`, `path`, `mode`, `os`, `status`, `user_agent`, `referer`, `time`) VALUES (\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",%d)" % (ip,path,mode,os_name,status,user_agent_name,referer,request_time)
# 统计纪录
stats_sql = ""
if user_agent_item[2] == "":
stats_sql = "INSERT INTO `db_stats`(`date_time`, `request_count`) VALUES (\"%s\",1) ON DUPLICATE KEY UPDATE `request_count`=`request_count`+1" % (date_time)
else:
bot_field = user_agent_item[2]
stats_sql = "INSERT INTO `db_stats`(`date_time`, `request_count`,`%s`) VALUES (\"%s\",1,1) ON DUPLICATE KEY UPDATE `request_count`=`request_count`+1,`%s`=`%s`+1" % (bot_field, date_time, bot_field, bot_field)
try:
cursor.execute(sql)
cursor.execute(stats_sql)
db.commit()
except Exception as e:
db.rollback()
print(e)
db.close()
def parse(line):
arr = line.split("\" \"")
if len(arr) != 6:
print("error format line:" + line + "\n")
return
ip = arr[0][1:]
request_time = arr[1]
request_line = arr[2]
status = arr[3]
ref = arr[4]
user_agent = arr[5][:-1]
mode = ""
path = ""
line_arr = request_line.split(" ")
if len(line_arr) == 3:
mode = line_arr[0]
path = line_arr[1]
else:
path = request_line
save(ip, request_time, path, status, user_agent, ref, mode)
if __name__ == '__main__':
print("monitor start...")
command = "tail -F " + log_file
popen = subprocess.Popen(command, stdout = subprocess.PIPE, stderr = subprocess.PIPE, shell = True)
while True:
line = popen.stdout.readline().strip()
line = str(line, encoding = 'utf-8')
parse(line)
(全文完)
(欢迎转载本站文章,但请注明作者和出处 编程想法 – Yuccn )