某网站防爬虫/防盗资源的实现和破防
逛某漫画站,有想弄个爬虫把图片爬下来的想法。
但发现该站的原图是被做了切割的。如果找图片链接,直接下载,是这个样子的:

眼好花是不?而实质上网站显示的图片是这个样子:

挺有意思的,估计该网站这样设计,是防爬虫或者防盗其资源吧。
可以知道其切割逻辑:
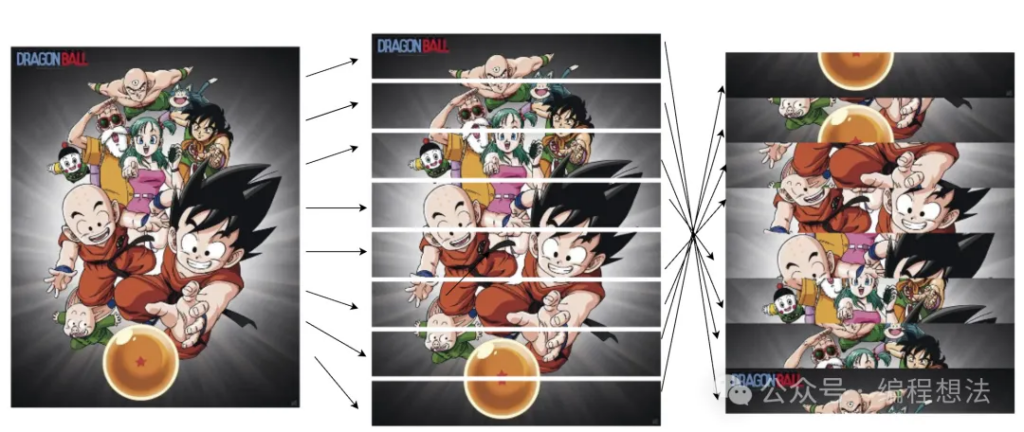
如果直接下载图片,图片就是右图那个鸟样。
通过开发者工具看看元素,发现该img 的style=”visibility: hidden;”,下面多了一个画布 canvas,如下:

大概可以知道该网站的思路了:网站预先把图片切割好,生成倒叙切片图片(切多少片不固定),前端通过脚本加载图片后,再把图片切片,用正确的顺序把片段draw 到画布上。
模拟该网站的实现
为什么要模拟它?没有为什么,就是写着玩玩。
直接上一个html 代码,为了简便,直接把js也写里面了。
大概就是这样:
<!DOCTYPE html>
<head>
<title>拆分图片</title>
</head>
<body>
<div id="container">
<img src="./00001.webp" id="album_photo_00001" style="visibility: hidden;">
</div>
</body>
<script>
// 实质使用上会单独到另一个文件(并且混淆),这里演示方便,扔这了。
function draw_image(canvas, image) {
var count = 8; // 实际上 count 是根据某些规则,这里演示,直接写死
var image_w = image.width;
var image_h = image.height;
var frame_h = image.height/count;
// 倒叙摆放,把它转回来
for (var i = 0; i < count; i++) {
var start_h = frame_h * (count - i -1);
context.drawImage(image, 0, start_h, image_w, frame_h, 0, frame_h * i, image_w, frame_h);
}
}
window.onload = function() {
// 加载图片
var image = new Image();
image.src = document.getElementById("album_photo_00001").src;
// 创建画布
var canvas = document.createElement("canvas");
canvas.setAttribute('width', image.width);
canvas.setAttribute('height', image.height);
context = canvas.getContext("2d") ;
draw_image(canvas, image);
var container = document.getElementById("container");
container.appendChild(canvas);
}
</script>
</html>运行效果:
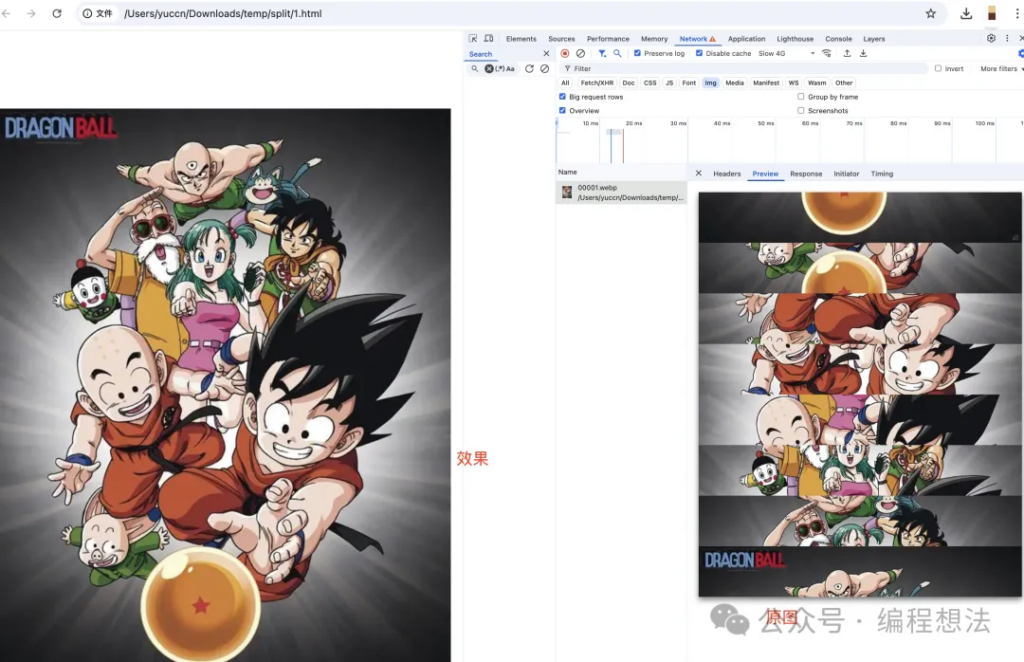
图片的破防的思路
demo可以固定切片数,但爬虫应该如何知道切片数?
分析该网站js代码,会发现有个函数计算它(根据“漫画id 和图片id”来计算),虽然这段代码被混淆了,但有前端分析功底的伙伴这个不是难事。
本文说说求得切片数的另一个思路。
由于图片是被均匀的横向切割再拼接的,所以图片会有明显的横行线条,这不,就可以用openCV 对其进行横向线条获取和分析了?!
步骤就是用 Canny 检测边缘,之后通过HoughLinesP 检测线条,过滤非水平线即可。
img = cv.imread("00001.webp")
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
edges = cv.Canny(gray,50,150,apertureSize = 3)
for line in cv.HoughLinesP(edges, 1, np.pi / 180, 100, minLineLength=10, maxLineGap=1000):
x1,y1,x2,y2 = line[0]
angle = np.degrees(np.arctan2(y2 - y1, x2 - x1))
if abs(angle) > 1:
continue
cv.line(img, (x1,y1), (x2,y2), (0,255,0), 2)如下,openCV 识别横向线条(画出绿色线标注)效果:

有了这些线条,便可对它们进行聚合整理(再做些基本的校验),不难得出切割的图片数多少。
识别出线条数,便可知道切片多少了(如上图,线条整合就是七束,也就是八块)。后面几乎就等价于用python 把上面js 写一遍,再保存新图片即可。
还原图片代码:
import cv2 as cv
import numpy as np
img = cv.imread("00001.webp")
emptyImage = np.zeros(img.shape, np.uint8)
# 根据识别结果填充,测试所以写定了。
count = 8
image_h, image_w, frame_h = img.shape[0], img.shape[1], int(img.shape[0] / count)
for i in range(count):
img_offset_y = i * frame_h
result_offset_y = (count - 1 - i) * frame_h
# 倒叙还原过来
for y in range(frame_h):
for x in range(image_w):
emptyImage[img_offset_y + y, x] = img[result_offset_y + y, x]
cv.imwrite("result.png", emptyImage)完整的爬站代码就不上了,本文主要是说说思路,有编程功底的看官,稍微整理下,整合一个防破的爬虫代码不是啥难事。
(全文完)
(欢迎转载本站文章,但请注明作者和出处 编程想法 – Yuccn )