比特币知识(6)——Merkle Tree
1 从下载一个大文件说起
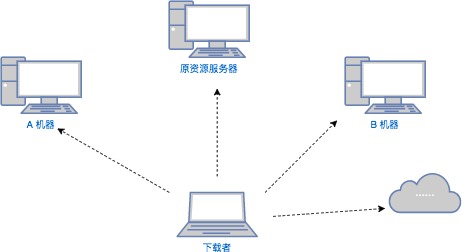
如果需要从网上下载一个很大的文件,如果该文件只有一个服务器上存在,下载源只有一个,那么下载的逻辑无可争议,就是下面这样了:

上图,也就是在p2p 技术出现之前的下载模式,单一的下载源,整个文件的数据都从一个服务器上面取。
这样的下载模式缺点明显:比如如果下载者过多,会导致服务器压力过大;又如如果下载异常而断开,那么整个文件都需要重新下载;再如如果服务器异常而关机了,那么就无法下载到该文件了等等问题。
2 简述Hash Lish
而现实中的一些资源文件(比如电影,游戏安装包),不会只在一个电脑上,比如A下载了资源后;B 再去下载时候,这时候原服务器和A 都存在该资源了;B下载了资源后,C再去下载……这样拥有该资源的节点就越来越多了。
如果能从多个资源节点上同时下载这个文件就好了。把一个大文件分割成许多小块,比如每个块大小为2KB,对每块文件进行编号,每块文件从不同的资源节点上下载,尽量多的在不同机器上下载不同小块,就算一个块出错,只需要重新下载这小块就行,而不需要重新下载整个文件,而且下载小块时候,尽量从和自己较近的节点下载,这样下载的速度就是飞跃一般的提升了。结构大概如下:
在不同节点上下载各块的时候,会涉及一个校验块是否正确问题,比如,在B机器节点上下载的小块,如何确保这个块的数据是正确的(下载时候出错或者B机器故意伪造假数据)?
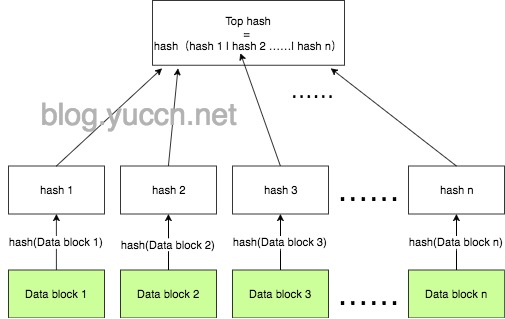
为了解决校验问题,那么就需要一些特殊的处理了——把这个大文件分成多个小块后,对各块算hash值,之后把这些hash 组织在一起,有下载者需要下载该大文件,就先(从可信的节点,一般是原服务器)下载好这个hash组织文件,之后再从其他机器节点上面下载各个小块的文件。各小块下载完成后算下hash 和组织文件的值做匹配,匹配的才算完成下载;如果不匹配的,那么这块就说明是坏的了。
在可信服务器下载hash组织文件时候,如何判断这个组织文件传输过程中没有出错?为了解决这一点,就需要把原本算好的hash列表拼接在一起,再算一次hash值,把该值放到该组织文件首部去。这样,既可以通过该文件检验大文件的各个小块,又可以用于自身的自校验了。该文件结构叫Hash List,逻辑图如下:
3 Merkle Tree 结构
Hash List 挺好的了,但应用上也存在着它的不足,也就促使了Merkle Tree的诞生。先来看下Merkle Tree 的结构,如下:
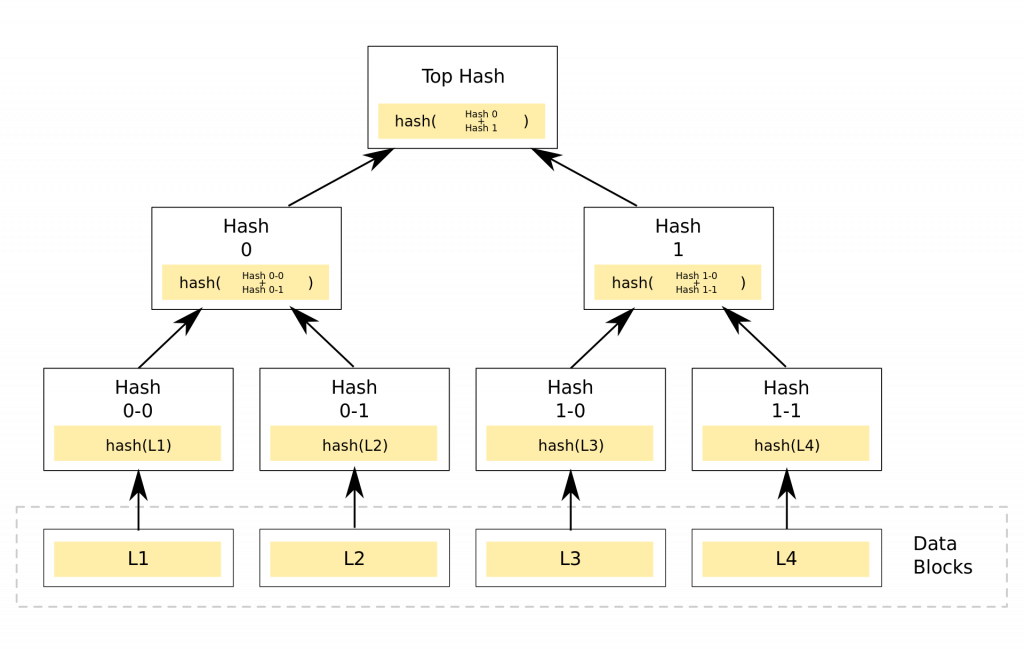
Merkle Tree 是这样组织在一起的(也就是创建,这里用2叉为例,也有多叉的):
1)对原来的小块进行算hash值,
2)得到的这批 hash值后,相邻的hash 值合并算hash。针对原来这批hash,可能存在奇数(非1)、偶数或1情况,分为3种情况:
-2.1)如果这批hash 个数为偶数时候,这批hash相邻的合并后算hash,得到一批新的hash,回到2)进行重复操作,
-2.2)如果个数为奇数(非1),前面两两相邻的合并算hash,最后一个值单独算hash,得到一批新的hash,同上回到2)进行重复操作,
-2.3)最后一步为个数为1的情况,进入3),
3)完成,得到一个倒挂的树形结构hash数据,树状组织在一起,这个就是Merkle Tree了,最后那步算得的hash,称为Root Hash。
可以看出其特点:
1)Merkle Tree是一种树,大多数是二叉树(也可以多叉树,但无论是几叉树,它都具有树结构的所有特点);
2)Merkle Tree的叶子节点的value是数据集合单元数据的hash;
3)非叶子节点的value是根据它下一层子节点值按照hash算法计算而得出的,也就是非叶子结点可以对其子结点值进行检验。
回头看看Hash List 结构,它是一个高度为2,分支为N的特殊的Merkle Tree。Merkle Tree比Hash list有明显的优点,在下载文件很大的时候,用Hash List 和Merkle Tree 都可以做到校验,但是Hash List需要下载整个list 才能校验,而Merkle Tree 只需要下载其对应的分支就可以做校验了。
也就是,在下载Merkle Tree 的时候,只需要Rook hash 从可信机器下载即可,其他的Merkle Tree分支可以从不同的机器上下载,分支下载后就可以下载对应的数据块了。各个分支的根可以对其子树进行检测,Rook hash 则可以对整个Merkle Tree 进行检测。这样就确保了整个大文件的完整形,而各个分支又可以独立处理。这优点是Hash List 做不到的。
4 Merkle Tree 的修改
上面说了Merkle Tree 对创建和特点,那么Merkle Tree 的对叶子结点的修改、插入或者删除呢?
Merkle Tree 叶子结点的修改较为简单,就是从待修改的叶子结点一直向父节点更新,一直到Root Hash 即可,需要改动的数据较少。
插入或者删除必然会导致Merkle Tree 结构的变化,如何确保Merkle Tree 的自身特点,在不同工程上有不同的需求,Merkle Tree的初衷不是为“常常变更的数据”做设计的,所以Merkle Tree的插入删除(包括修改)懂统一算法,是没有意识的。试想,一个电影或者一个程序安装包,里面的某块数据会常常变动?
5 Merkle Tree 在比特币中的应用
在文章“区块链基础”提到,每个区块内的数据有PrevHash、Nonce、Timestamp,Hash和transaction。其实在区块头是不包含transaction信息的,它包含的数据就是这个区块内的交易生成的一个Merkle Tree的那个Root Hash节点。如下:
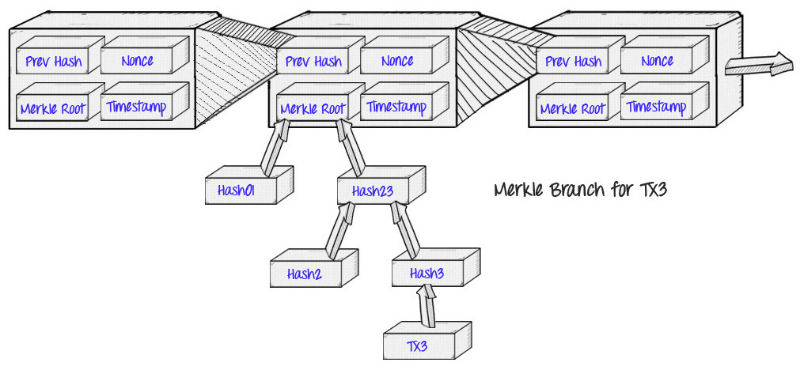
而这样做的好处就是,可以仅下载区块头而不需要下载整个区块下的每一笔交易及其每一个区块(否则这个数据量是很大的),也就是“简化支付验证”(Simplified Payment Verification,SPV)。区块头大小为80字节,按照每小时出6个区块的速度,一年增加的区块头大小约4M, 即使是目前底端的设备,对于这个增量也是能够负载的。
如果一个轻客户端希望确定一笔交易的状态,它可以简单地请求一个Merkle proof,这个请求显示出这个特定的交易在Merkle tree的一个叶子之中,而且这个Merkle Tree的Rook hash在主链的一个区块头中,那么就可以确认这笔交易在区块链中了。确认步骤:
1)从网络上获取并保存最长链的所有区块头信息;
2)计算该交易的hash值——tx_hash;
3)定位到包含该tx_hash所在的区块,验证其区块头是否包含在已知的最长链中;
4)从区块中获取构建Merkle Tree所需的hash值;
5)根据这些hash值计算出Merkle Tree的root_hash;
6)若计算结果与区块头中的Merkle root相等,则交易真实存在。
6 Merkle Tree 在其他的应用
Merkle Tree的应用点挺多的,包括Git,Certificate Transparency framework,NoSQL systems等。
(全文完)
(欢迎转载本站文章,但请注明作者和出处 编程想法 – Yuccn )