通过机器学习,进行识别脸部,给人物佩戴眼镜的实现「python实现」
上一文,《通过简单例子介绍 Python 快速创建和优化Gif图片》,使用的例子为马总加个眼镜,但是眼镜并不会动,略为生硬。

这篇,使用机器学习知识,对其眼镜进行矫正。
主要思路:识别脸部,得到脸部位置,对眼镜位置进行调整。
1 环境依赖本位主要是用OpenCV,OpenCV在Linux、Windows、Android和Mac OS系统都有对应的库,本文运行环境在Mac:
pip3 install opencv-python
pip3 install opencv-contrib-python
pip3 install opencv-python-headless其它环境按照自情况进行命令按照即可。
2 基本使用
人脸检测实际上是对图像提取特征,Haar特征是一种用于实现实时人脸跟踪的特征。Haar 具体逻辑可以参考:https://zhuanlan.zhihu.com/p/152305364,不感兴趣的话无视,我们直接使用就可。
OpenCV给我们提供了Haar特征数据,在cv2/data目录下,使用函数detectMultiScale。
# def detectMultiScale(self, image, scaleFactor=None, minNeighbors=None, flags=None, minSize=None, maxSize=None)
# 参数说明:
# scaleFactor: 指定每个图像比例缩小多少图像
# minNeighbors: 指定每个候选矩形必须保留多少个邻居,值越大说明精度要求越高
# minSize:检测到的最小矩形大小
# maxSize: 检测到的最大矩形大小使用可以直接识别出脸部:
import os
import cv2 as cv
def face_detect(image):
# 将图片转换为灰度图
# 灰度图会大量减少图像处理中的色彩处理,对人脸识别很有效。
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
# 加载脸部特征数据
face_detector = cv.CascadeClassifier(os.path.join(cv.data.haarcascades, 'haarcascade_frontalface_default.xml'))
faces = face_detector.detectMultiScale(gray)
# 脸部数据
for x, y, w, h in faces:
# 绘制脸部区域
cv.rectangle(image, (x, y), (x + w, y + h), color=(0, 255, 0), thickness=2)
image = cv.imread("data/1698656382550.jpg")
face_detect(image)
cv.imshow('image', image)
cv.waitKey(0)
cv.destroyAllWindows()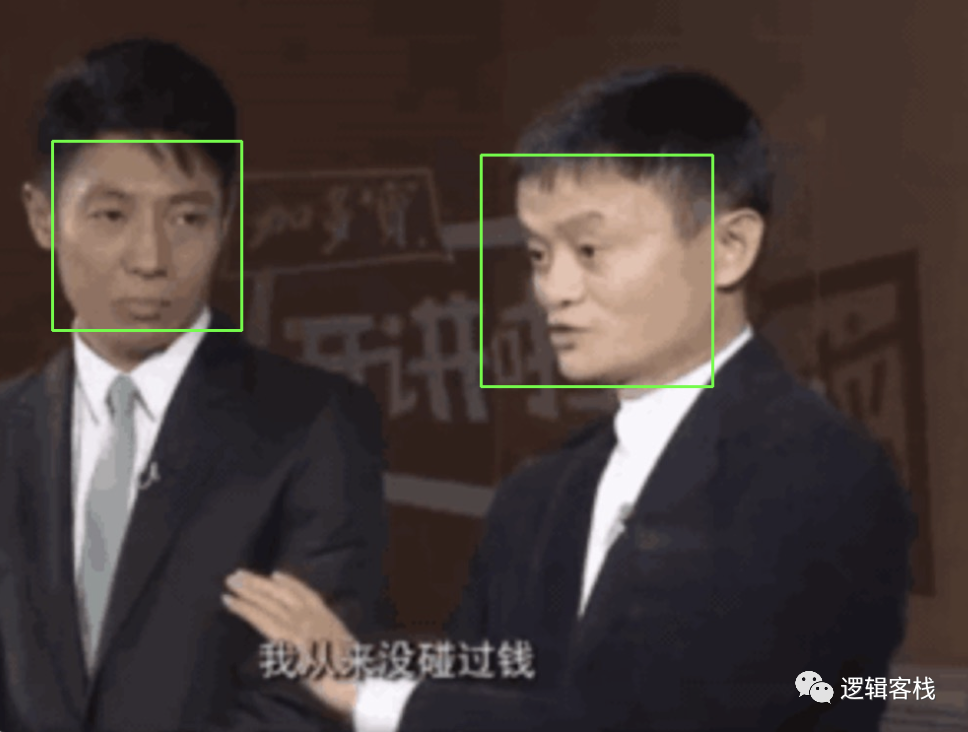
使用cv.VideoCapture可对视频文件、gif 文件处理,增加代码:
cap = cv.VideoCapture("data/src.gif")
while cap.isOpened():
success, frame = cap.read()
face_detect(frame)
cv.imshow('result', frame)
if ord('q') == cv.waitKey(10):
break
cap.release()
cv.destroyAllWindows()效果:

这样识别出来的结果,不仅马总,撒贝宁的脸部也被识别出来了,如果要佩戴眼镜,两个人都带上?撒贝宁说:不戴,我对钱感兴趣。
这就用到机器识别部分,对马总的脸部进行数据训练。
3 数据训练
需要进行脸部数据训练,就需要大量马总脸部的图片数据,这里没有那么多数据,做等价的数据处理,把原gif 图片上的脸部就行抽取出来训练算了。
使用前面PIL库对gif 图片进行图像剪裁抽取:
i = 1
for f in ImageSequence.Iterator(img):
path = "data/face/%d.png" % i
f = f.crop((300,40, 480, 240))
f.save(path, quality=80)
i +=1得到头像数据如下
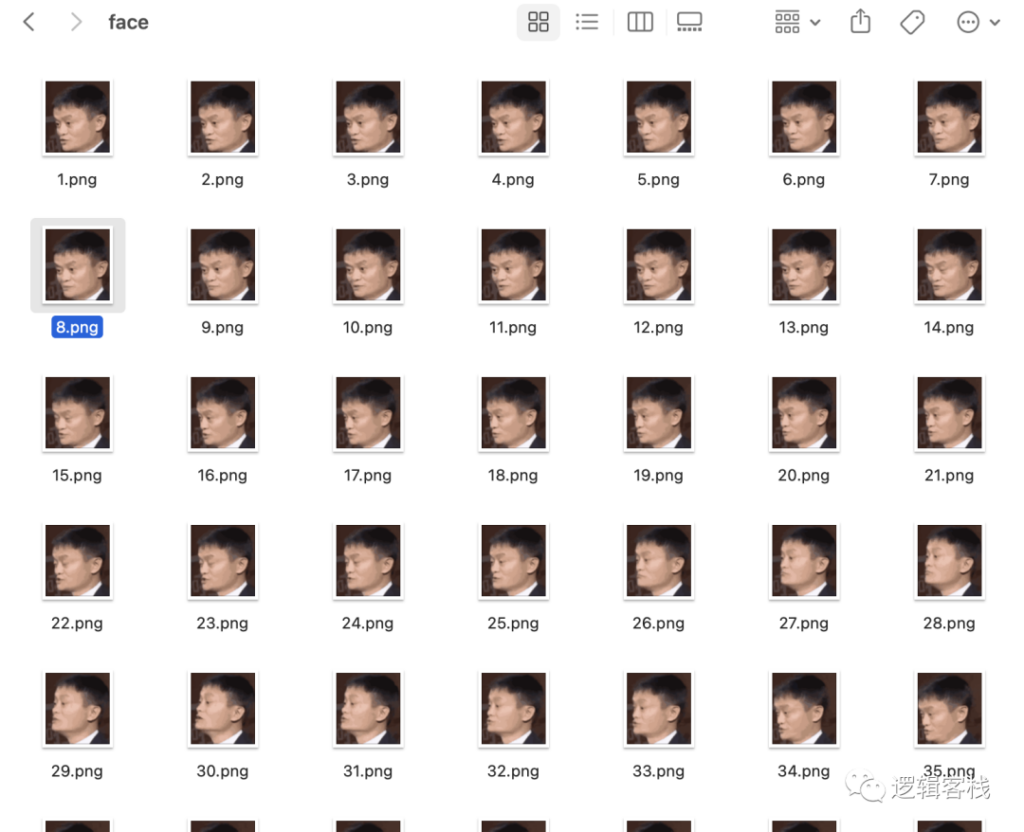
再使用LBPH训练模型
def buildFacesLabel(path_list):
_faces = []
_ids = []
image_paths = [os.path.join(path_list, f) for f in os.listdir(path_list) if f.endswith('.png')]
face_detector = cv.CascadeClassifier(os.path.join(cv.data.haarcascades, 'haarcascade_frontalface_default.xml'))
for image in image_paths:
img = cv.imread(image)
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(gray)
_id = int(os.path.split(image)[1].split('.')[0])
for x, y, w, h in faces:
_faces.append(gray[y:y+h, x:x+w])
_ids.append(_id)
return _faces, _ids
faces, ids = buildFacesLabel('data/face')
# 训练
recognizer = cv.face.LBPHFaceRecognizer_create()
recognizer.train(faces, np.array(ids))
# 保存训练特征
recognizer.write('trains/trains.yml')4 基于LBPH的人脸识别
代码需要稍微修改下,加入少量代码:
def face_detect(image, recognizer):
# 将图片转换为灰度图
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
# 加载特征数据
face_detector = cv.CascadeClassifier(os.path.join(cv.data.haarcascades, 'haarcascade_frontalface_default.xml'))
faces = face_detector.detectMultiScale(gray)
for x, y, w, h in faces:
# 获取置信度,大于50忽略
_id, confidence = recognizer.predict(gray[y:y + h, x:x + w])
if confidence < 50:
cv.rectangle(image, (x, y), (x + w, y + h), color=(0, 255, 0), thickness=2)
recognizer = cv.face.LBPHFaceRecognizer_create()
recognizer.read('trains/trains.yml')
cap = cv.VideoCapture("data/src.gif")
while cap.isOpened():
success, frame = cap.read()
face_detect(frame, recognizer)
cv.imshow('result', frame)
if ord('q') == cv.waitKey(10):
break
cap.release()
cv.destroyAllWindows()效果如下:

基于识别出马总脸部,再对其位置进行佩戴眼镜操作便可。
有了上面的逻辑,再做加工整理下代码,封装一个脸部的区域获取,根据其区域进行眼镜位置调整,把上一文(通过简单例子介绍 Python 快速创建和优化Gif图片)的代码结合整理,便是最终代码了。
最终代码如下:
def getFaceRects(img, recognizer):
result = []
path = "tmp/%d.png" % random.randint(0, 10000)
img.save(path, quality=80)
image = cv.imread(path)
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
face_detector = cv.CascadeClassifier(os.path.join(cv.data.haarcascades, 'haarcascade_frontalface_default.xml'))
faces = face_detector.detectMultiScale(gray)
for x, y, w, h in faces:
_id, confidence = recognizer.predict(gray[y:y + h, x:x + w])
if confidence < 80:
result.append([(x, y), (x + w, y + h)])
os.remove(path)
return result
recognizer = cv.face.LBPHFaceRecognizer_create()
recognizer.read('trains/trains.yml')
img = Image.open("./data/src.gif")
glass = Image.open("./data/glass.png")
frames = [f.copy() for f in ImageSequence.Iterator(img)]
new_image = []
for frame in frames:
rects = getFaceRects(frame, recognizer)
if len(rects) == 0:
continue
rect = rects[0]
frame.paste(glass, (rect[0][0], rect[0][1]), mask = glass)
new_image.append(frame)
new_image[0].save("./data/dst.gif",
save_all = True,
append_images = new_image[1:],
loop = 0)
cv.destroyAllWindows()效果:

本篇是简单的opencv脸部识别+机器学习的介绍,属于入门级别,不做更深入的介绍了。效果还行,比原来的古板的眼镜生动多了。
(全文完)
(欢迎转载本站文章,但请注明作者和出处 编程想法 – Yuccn )